近日,北航国新院人工智能科创中心科研团队研究成果Remodeling Semantic Relationships in Vision-Language Fine-Tuning在全球人工智能国际顶级学术会议“AAAI人工智能大会”(AAAI Conference on Artificial Intelligence)上发布。北航国新院人工智能科创中心2025级硕士生吴湘阳为第一作者、刘柳教授为通讯作者。该研究由北航国新院、人工智能学院、宇航学院联合开展,并与新加坡南洋理工大学(Nanyang Technological University)、英国莱斯特大学(University of Leicester)等国内外科研机构合作完成。

原文链接:https://arxiv.org/abs/2511.0823
AAAI人工智能大会是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议,会议涵盖了人工智能领域的各个方面,包括理论、方法、应用和实践,吸引了来自全球学术界和工业界的顶尖研究人员和从业者参与。本次AAAI2026共收到23680篇投稿,其中4167篇被录用,录用率为17.6%。AAAI2026会议将于2026年1月20日至1月27日在新加坡举行。此项科研成果的录用发表,标志着北航在人工智能基础研究领域取得了扎实的原创性进展。

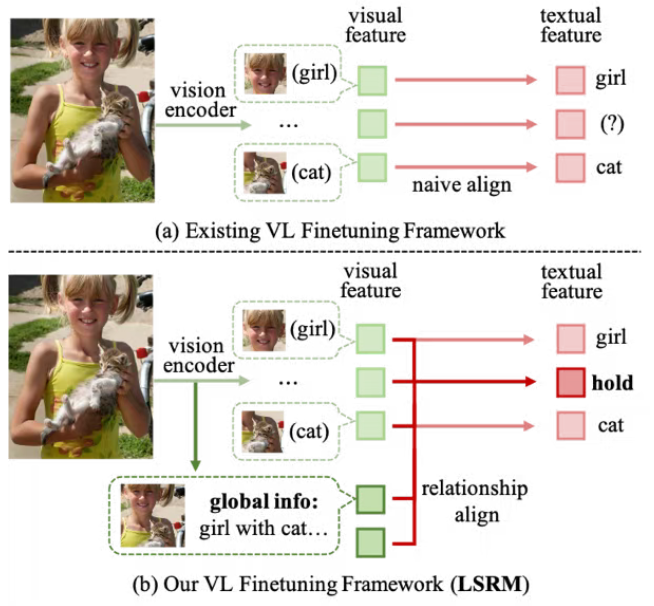
随着多模态技术的发展,视觉组件的引入为大模型装上了“眼睛”,使其具备同时处理图像和文本输入的能力,从而适配更广阔的应用场景。而随着应用场景日趋复杂,多模态任务不再拘泥于单一目标的识别,更需要文本提示下对多图像实体的综合理解。例如,对于一张小女孩抱着猫的图像而言,模型不仅识别出“小女孩”、猫这样的语义实体,更要理解“抱”这一关联信息。吴湘阳等人提出的新型视觉语言模型训练框架LSRM(Learnable Semantic Relationship Method),创新性地将视觉编码器内部层的多实体语义关联信息重新利用,并在视觉语言信息的融合阶段引导模型对多实体关联进行建模,使模型自发地关注并学习图像内各语义实体的关系。
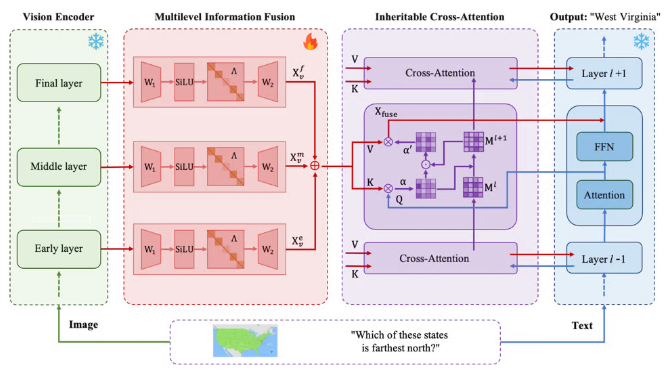
△实验结果及流程图
现有以CLIP为代表的视觉编码器虽能很好地识别图像中的各语义实体,但由于其训练目标性质的制约缺乏建模语义实体间关系的能力。而本研究注意到,即使末层输出存在独立实体建模的偏好,抽取内部层输出可以在编码器分离各实体语义前保留实体间的关联信息。因此,LSRM采用多级信息融合(Multilevel Information Fusion)的方法进行信息聚合,同时利用两类输出的优势。同时,LSRM通过改进投影器和注意力层结构的方法,增强了视觉信息和语言信息融合时的关系建模。新型训练框架在仅增加微小的训练代价的基础上,显著提升了视觉语言模型的性能,特别是在多语义实体的关系建模方面。实验结果显示,LSRM在八类预训练模型和两类下游任务中显著超越现有框架,展示了强大的通用性和跨模型适配能力。
LSRM的提出是北航人工智能科研团队在基础理论和工程创新结合上的又一次成功探索,也展示了学校在培养具有国际竞争力青年科研人才方面的持续投入与成果转化能力。未来,团队将继续深入探索视觉语言模型的复杂任务建模能力,使模型的“眼睛”与“大脑”的配合更加紧密,推动人工智能技术适配更困难、更广阔的应用场景。
(审核:董卓宁 陈龙飞 吴文峻)





 最新动态
最新动态